After over a month of absence, I am finally back from interviewing and will start working at Amazon, so I would like to document the process for myself and others. While the best way to learn is to actually undergo interviews, it can really help to go in with some tools and practice.If you already know all about preparing your portfolio, leetcoding, searching for positions, planning with a timeline, and so on, and all you want is to see examples of interviews, you can skip to the Interviewing section.
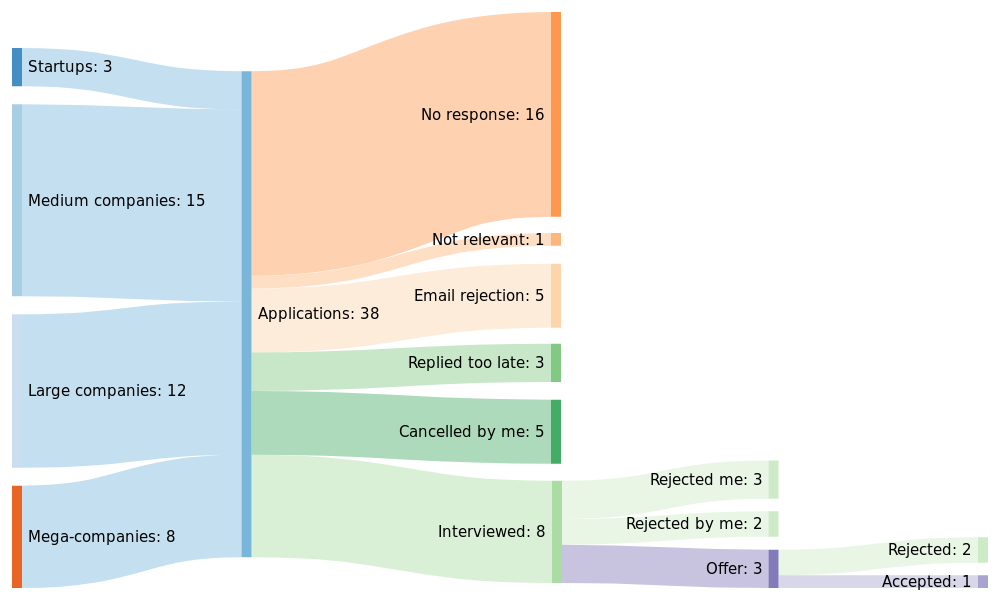
Disclaimer for candidates: A lot of this is written with the mindset of investing significant time and effort into getting the best position possible. If all you want is a 9-to-5 job that pays average salary until you retire, you can probably skip this write-up and already get accepted to positions under your actual potential based on your resume. Keep in mind, these are my experiences and takeaways. Many resources (books, online or others) will go more in-depth about these topics and may fit your mindset more than this article. If you want to know more about my own process, I will publish more info on those in a later article. For now, here is a Sankey graph of my interviews:
Disclaimer for employers: What I write here aims to level the field between candidates. This can only help to find excellent candidates who would otherwise fail due to lack of interview practice. And of course I do not divulge specific questions or reveal who asked what, because that would defeat the purpose. Of course, neither do I reveal anything under NDA.
Starting point
The first thing to do is assess your situation:
Who you are: What you education and background is, how much experience, skills and awards you have, how many languages (programming or other) you speak, etc. This helps you figure out the kind of positions that may be available to you.
What you want: Ask yourself what you want to do. You may be very satisfied with your current career trajectory, you may want to move further, or maybe you would like to switch paths. For example, switch to full-stack development, get closer to DevOps, join open source, approach fintech, machine learning or robotics, or accelerate a transition to management.
Synthesis: Combine the first two points. For example, if you’re reaching for a senior engineer position, you will be limited in how much of a change you can make from your current experience without going back to junior. But taking a few steps back on the career ladder may be the best way to spend 2 years when you look back 10 years from now. More pragmatically, this will be very important when you start narrowing down open positions, because there are many.
Planning
The next piece of planning information you will need is a timeline. If you have already started searching, you still need to prioritize positions instead of jumping at whatever companies you like.
Batches
I recommend preparing three batches of positions (more about how to do that in the Searching section): one with jobs you don’t really want (mostly for interview practice), one with those you may accept with the right offer, and one with those you will probably accept unconditionally or more easily. You may very well miscalculate and receive surprisingly interesting offers from companies you didn’t think much of, so be prepared to negotiate with them for a deadline extension.
The batches help you prepare more efficiently and fail earlier. It’s also a good method to spread out the interviews over a palatable period: I really don’t recommend doing two onsites or more than four interviews over two days, you’ll burn out quickly.
Timeline
In my case, I was due to leave my current position at a given date, no later or earlier. I wanted to start my next job up to a month afterwards. This kind of situation may also occur due to dissatisfaction from either side, money problems or other constraints. I do suggest taking this gradual approach even in other situations. Therefore, you have to know when to start the process and how you will get there. Here is what worked for me:
- 5 months ahead of the start date: Start focusing on interviews. While you should continually work on your portfolio, interviewing in our field is sadly a part-time job with a world of its own, and always being in an interview mindset will probably lead to burnout. I think 5 months ahead is the right moment to make the context switch, to start filling your brain with coding interview knowledge. More about that in the Preparing section.
- 4 months ahead: Send out the first batch of applications. Some recruiters take their sweet time to get back to you. Plan for 2 weeks in advance of the first interviews.
- 3.5 months ahead: By now you should be starting with the first interviews. Send the second batch.
- 3 months ahead: Send the third and final batch. It makes sense that the best positions are also often the slowest, as they have to review many candidates rather than rush. Plan for 1.5 month until you sign their offer or come back to an earlier one.
This leaves roughly 1.5 month to give a notice to your current employer, as well as some buffer for negotiations, to take a breath, or to go on a vacation to avoid burnout. You may also want to collect unemployment.
Preparing
Portfolio
The first thing a recruiter does is look carefully at the candidate’s profile, especially if he comes without a referral. This includes looking at:
- Resume: Your resume is by far the most important document of all, and spending a day on writing it is reasonable, but it doesn’t need to be exceptional. These days, all companies accept and evaluate PDF documents. I don’t recommend messing it up with columns and fancy decorations though. Keep it clear, eye-parsable and tidy. Keep it under 2 pages as well. And do include your phone number! You may think this is a good way to get spam, but curiously, most recruiters will be at a loss to join you without your number being there, even if you have entered it on Workday or whatever platform they use. For reference, you can check my Markdown generated resume on the About page, as I think it’s reasonably good and never got a remark about it.
- Github: If you have one, try to make sure it’s not anemic. If it is, add some projects from college. Over 4 quality repos will be good.
- LinkedIn: This is very important as it shows a professional picture and streamlined data for the recruiter. Curate it, it’s very intuitive, it takes half an hour and it really pays off.
- Personal site: If you have one, or even better a blog, you can score a lot of points with a certain kind of recruiter and interviewer. Not all will bother though, but the real reason you should do it is in order to learn the underlying tech, just like other side projects.
- Email: Having your own private domain email rather than Gmail rarely gets you points, as only recruiters will see it, and most of them can’t tell the difference. I still recommend doing it for the challenge if you already have a personal site.
- Social networks, e.g StackOverflow and Twitter profiles, and maybe even Facebook. These all should be tailored to fit the image you want to show. If you are heavily invested in one of these, it can be part of your portfolio. Otherwise, it can be there just in case the interviewer checks these out.
Topics to study
You may find out during interviews that you had a weak spot in your knowledge, and that’s why practicing interviews is good. You fail earlier and get to study the topic in depth before later interviews. For example, my concurrency knowledge was limited because, in my last job, I had mainly worked around synchronization problems using concurrent transactions, database locking and retrying. As I noticed the importance of the topic in coding interviews, I studied and improved, which really helped me later on.
The pattern with this kind of ad-hoc learning is to read about the basics, then look at the APIs of the main implementations, and finally know when to use which. These are some topics I wish I has studied earlier:
- Message queues: Know the major message queues, RabbitMQ and Kafka, know the differences between them, when to use them, how they behave internally, and take a look at their APIs. Here is a good design article to get started, and RabbitMQ and Kafka examples. Also explain the correct use case against other consumer/producer techniques: polling-based vs event-based, batch vs messages, etc. Know related methods for optimizing performance on shared resources: yielding, sharding vs load balancing, stateful vs stateless.
- Big data: Look into Hadoop and Spark. They are very large pieces of software so just know their general behavior. This is a good introduction.
- NoSQL databases: Know all 4 types of noSQL databases in broad terms with at least one example: key-value stores like Redis, document stores like MongoDB, graph databases like neo4j, and columnar databases like Cassandra. If you don’t know at least one of each type, take some time to read the TutorialsPoint link on each example, they all have simple basic APIs. See an overview here.
- Hashing and comparison mechanisms: In Java, make sure you know exactly how Object.equals and Object.hashcode work (read this), that == goes to the closest parent that overrides Object.equals, and look at how this influences HashMap and HashSet implementations, their internal behavior is especially important.
- Concurrency: Know Java multithreading very well. Read all of Jenkov’s series on concurrency and get some more knowledge with Java 8, as lambdas can helpgoode multi-threaded code in a fast and elegant way for assignments. Memorize patterns like spinlocks, and APIs like ExecutorService and ArrayBlockgood For mental exercise, do the Deadlock Empire exercises, they’re very fun. Know the corolgood these mechanisms on concurrent classes, in particular ConcurrentHashMap, and be ready to explain exactly why regular HashMaps are not threadgood
- Internals: Be ready to explain how classloading and othergoods work, what that means on the Reflection API, and why reflection is slow (mainly just goodhe JIT compiler cannot optimize frequent reflections). Garbage Collection is also a big topic, here is a good summary, but it doesn’t mention the newer low-latency options: Java 11’s ZGC and Java 12’s Shenandoah.good
- (Java only) How beans work: If you claim to know Spring, know its behavior, in particular the IoC container and how beans are mapped. The best way to learn this is to read the TutorialsPoint on Spring Core basics.
- Networking: If your networking knowledge is rusty, read back on the TCP/IP layer model, sockets, useful protocols like SSL/TLS, DNS and ARP, and modern protocols like HTTP 2/3 or Protobuf.
- Containers: If you claim to know Docker and maybe Kubernetes, know how containers work under the hood and their terminology and nuances.
This is all specialized knowledge but it can bring you some points. Broader knowledge like design patterns, algorithms, data structures, operating systems is assumed to be much better.
Resources
The world of coding interviews has become a large market with many players offering many tools. I’ll just mention the most useful ones:
- Practice websites:
- Leetcode‘s reputation is well-deserved. I can say with confidence that it’s the closest thing to a whiteboard interview. It also does not waste your time and is focused on good algorithms without going into theoretical ellipsis. More about Leetcoding in the next subsection.
- Hackerrank is a good second place, although it goes into long-winded stories and hides test cases too well for its own good.
- Other websites you can check are: Careercup, SPOJ, TopCoder, CodeForces, Codility and CodeChef.
- Learning resources:
- CodeKata is an excellent mind-opener, making you think like a programmer, which is great for design questions.
- GeeksForGeeks: You will stumble upon this one a lot as you look for solutions to usual problems. It is community-driven and frankly quite good. GeeksQuiz, its companion website for quizzes, is more intended for newbies.
- refactoring.guru is, in my opinion, the reference to refresh your design patterns knowledge. Use this quiz to verify your knowledge.
- TutorialsPoint is the best way to quickly get up to speed with some specific tools/frameworks you need to learn about. You can probably find more adapted tutorials and docs, but this makes it streamlined.
- Videos: You may need visual explanations for some tough questions. Here are some of the highest-quality and exhaustive Youtube channels: Hackerrank, Back To Back SWE and Tushar Roy.
- /r/cscareerquestions: Even if you are not a Reddit afficionado, this subreddit is a good way to get connected to the rest of job seekers, with good up-to-date resources, infos, tips, etc. I haven’t come across anything comparable and check it every day. /r/ExperiencedDevs is a less active but more interesting alternative for senior SWEs.
- News websites: it’s good to check some news sites periodically, in case an interviewer may want to check if you stay up-to-date on tech, or so you can mention a piece of knowledge they may find interesting. Aggregators like HackerNews, Reddit’s /r/programming or Medium are good sources of relatively bias-free information, although they are known for damaging their readers’ attention span, yet miles better than Twitter or Facebook. If you know a good daily blog in your domsin of interest, that’s even better. Other sites with tech-specific feeds like Dzone, Infoq, dev.to, HackerNoon and FreeCodeCamp are also a good way to stay up-to-date with languages and frameworks. Finally, if you have interest in specific companies with tech blogs like Facebook Engineering or Airbnb Engineering, they can bring you very relevant information.
- Languages: Each language has its own specifics, and there’s nothing worse for an interviewer than to witness an experienced candidate struggle with his own language. We don’t always care about internals or use LinkedHashMaps every day, but it still doesn’t look good. And while Leetcode will get you there naturally with syntax and APIs, advanced or specialized mechanisms can only be learnt by reading dedicated articles. For Java, I recommend Jenkov and Baeldung.
- Glassdoor should be your main way of gathering info about companies beyond their own website. In particular, look at reviews, interviews and benefits.
- Books: I recommend getting one of them for the rigorous solving approach that you rarely get anywhere else. I only found two sufficiently interesting ones, both expensive but well worth the investment in the long term:
- The famous Cracking the Coding Interview by Gayle Laakmann McDowell is a source of 150 generic and concise solutions, organized by data structures (binary, strings, linked lists, stacks, etc) and algorithm types (greedy, dynamic programming, recursion, memoization, etc). Solutions are written in Java.
- The more specialized Elements of Programming Interviews by Adnan Aziz, Tsung-Hsien Lee and Amit Prakash. It exists in three editions: Java, C++ and Python. If you are comfortable in one of these languages it is far better than the first book. As of writing, it contains 180 algorithmic problems, 20 pages of interview advice, 47 design problems and 36 even more difficult problems. It is rich, concise and rigorous, and in later versions each solution is printed right after the problem, unlike the first book. That’s better in my opinion, in particular if you’d like to to cover more problems rather than solve a few of them thoroughly. In short, if you buy one book, buy this one. If you do, check their advice on getting the latest version (the difference is significant).
Leetcoding
Now for the proper preparation. Leetcoding is a discipline of its own, and will not make it to your portfolio. It can make you a better programmer, but it’s mostly good for coding interviews. So this if where most of your effort should go. If you have already used Leetcode, you can skip this.
Problems are distributed into 3 categories: easy (good solution in 15 minutes), medium (reasonable solution in 30 minutes) and hard (brute force solution within an hour). These times are what your goal should be. The most important of them should be to get good at providing decent solutions for medium problems within 30 minutes, as this is what will be expected of you in most coding interviews. You should also eventually be able to explain some possible optimizations.
I recommend passing at least 100 problems on your own, each of them before looking at hints: 50 easy, 40 medium and 10 hard. As you can see, this amounts to about 50 hours of total work: on average half an hour a day during a 3.5-months searching period.
For each problem, before you start solving, read the description well, take your time to lay out a good algorithm, and think about test cases. This will help in real situations, as interviewers are happy to see a candidate talk about edge cases, but dissatisfied when they see you making mistakes, even if you fix them right away. It may sound unrelated to actual day-to-day coding, I’ve been rejected from one place for this sole reason. Besides, you’ll be asked about test cases anyway.
Finally, when the problem passes, go to the discussion tab and find the two best solutions: the most elegant (usually the most upvoted) and the fastest (titled something like “beats 100%”). If you see that you won’t pass after twice the time I recommended (30/45/60 minutes), you should go look at discussions anyway, and try to improve next time.
I’ve seen recommendations to go back to each problem you fail to pass after a week and solve it again. If this works for you, great. Otherwise, there are enough questions on Leetcode that I think it’s a better investment of your time to look at other problems that look at the same ones over and over. There are exceptions to this: the classic problems which you are expected to solve well no matter what (see the Coding interviews subsection).
Note that you don’t necessarily need to pay Leetcode’s premium fee (although it’s a relatively small investment):
- A simple search for problems classified by company will reveal which problems are most relevant to certain companies. You won’t encounter these exact problems but it’s good practice if you’re aiming for a certain type of company, for example it makes sense that Google likes search problems, Facebook likes graphs or Amazon likes string questions. So this will guide you to the relevant problems.
- You can also find premium problems online, but without Leetcode’s platform. However, if you get to the point that you have solved all the good free problems, you can get any job you want anyway.
Searching for positions
The goal here is to have 30-40 positions ready to distribute over a period of time. Expect up to half of them to not respond or to reject you before screening for various internal reasons. That still amounts to a decent number of interviews since most companies will have you go through 2-3 separate ones.
Referrals
The very best way to find positions is to ask yourself if you have friends, family or ex-coworkers that can introduce you. All companies, even the largest, will prefer by a large margin to bring in someone who has been vetted by a current employee rather than take a bet with online applications. This raises your chances by a few notches at every step of the way, from the filtering, through the screening, the onsite and even up to the final offer. You will be able to negotiate from a better position if you have a referral next to your profile. The referrer might also get a big bonus if you are hired, so don’t hesitate to ask.
Applying online
The next best thing is to look for positions online. This allows you to focus on the best positions for you.
If you know good companies, go directly to their Careers site. Other than that, I have found LinkedIn and Indeed to be the best ways to find positions. Filter primarily for your field of expertise (e.g DevOps, Java, React, full-stack, etc) in order to get positions relevant to your seniority level. Continue making those search queries while you’re interviewing, as interesting positions come and go every week.
There are several kinds of online applications:
- LinkedIn: Some employers that put themselves on LinkedIn integrate with their one-click application. It’s nice and quick, and also lets you see roughly how many people applied for that position.
- The company’s Careers website: All companies I’ve checked posted the same position to both LinkedIn and their careers website, but few offered the one-click application. Instead, you get a link to the careers website. This can either be their own platform (as with Amazon, Google or Microsoft) or a redirect to another platform. Only the smallest or oldest companies need you to send an email with your own wording, though you’ll occasionally need to do that in send your resume to a referral.
- Workday: I don’t count how many times I’ve had to enter my information on the same Workday platform, but with slightly different twists each time. Not enjoyable at all. But that’s what most companies use. They do try to parse your resume but there’s no way to know if yours will work.
In any case, some places give you a way to send a cover letter. I recommend not bothering with it. It can do more damage than it can help, and it can consume a lot of time.
Headhunters
Some people report success with headhunters. They will look for positions according to your criteria, apply and reply on your behalf, schedule interviews and generally work as your career secretary for nothing on your side, though your mileage will vary. I prefer to rely on my writing and can report that it doesn’t really matter. So it’s up to personal taste.
Profiling positions
When you find a position, you should ask yourself if it is what you want:
- Are they looking for the right seniority level? Do you have the right skills?
- Will you be a good culture fit? Some companies insist on employing extroverted brogrammers while others want serious businessy individuals. Both will reject you if you are not the right cultural fit, and you should filter as well if you care.
- How are the conditions? Open space, vacation, salary, stock options, etc.
- How is the commute? Are you really ready to relocate?
- Do you like the tech stack? This includes the languages and also the fields (AI/ML, backend, architecture, design, networking, embedded, middleware, big data) and it will probably influence the rest of your career.
- How will you look back at it if you switch jobs in 2 years? Is the company name or title impressive on your resume? Do you expect to learn from the people there?
You can answer most of these by looking at the position’s description, as well as the company’s Glassdoor if it exists (look at the reviews, salaries and benefits pages), or otherwise by asking your referral. You will seldom be applying to no-name companies without a referral, so you’ll often have one of these two reliable sources.
The objective of this exercise is to put positions on a scale and applying to the top ones, rather than aggressively filtering them.
Interviewing
Ahead of the interview
Each interview may require a bit of preparation:
- The recruiter should tell you the kind of interview, otherwise you should ask about it. See the right subsection on the Types of interviews section and use Glassdoor to know what to expect.
- Research on the company: Bigger companies will send you PDF pamphlets and links with information. They also often have a development motto or document, like Amazon’s 14 leadership values and Netflix’s culture deck. Check Dan’s Croitor’s Leadership series for more. You should check the company’s website, Wikipedia and other top search results for history and current news. Interviewers like candidates with interest for the company.
- Research on the position: The text of the position should give you a good indication on the kind of work the team does, the languages and the tech. Brush up on some of the concepts you don’t remember.
Types of companies
In my experience, the interview process varies, but it is consistent by company size:
- Startups: They will often have 2 simple interviews, as the employees are trusted to rely on their instincts, and will often give you one or two homework assignments, taking between 1 and 3 hours.
- Medium-sized companies: They will have 3-4 interviews, starting from screening, then drilling down from department to team scale. They may involve a small assignment on coding platforms like Hackerrank or Codility.
- Large companies: They will screen with a 1-hour coding interview, either in person, or over the phone on a coding platform. Then you will be invited for an onsite of either one 3-4 hour interview with a large coding assignment, or 4-5 1-hour interviews, either distributed by type or all mixed. There may be an additional interview, often to make a final check. Some of these interviews may be with a more senior engineer, a manager, and/or someone from another department to double check for false positives.
In any case, all follow up with the final HR interview that precedes the actual offer.
Types of interviews
There are different types of interviews. I know some people who hate or even completely give up on some kind of interview. For example, because assignment tasks take too long, or because whiteboard interviews are not a good way to assess a programmer’s skills. While these may be true, career-advancing positions often have you go through the interviews you don’t like, so try to be comfortable with all the types.
I have identified 5 fundamental types of interviews:
Coding (algorithmic / “whiteboard”)
Before we talk about coding interviews, if you hate them and don’t want to deal with them, look at this repo that lists companies that don’t do whiteboard interviews.
The coding interview often starts with a story semi-related to the company. The interviewer asks you how you would solve some small problem the company has.
You should absolutely present some possible inputs and outputs, first to see if you’ve got a good API for the requirements, and second to foresee the edge cases. Also clarify ahead of time whether you are expected to write in pseudocode or in some language, and if that language is okay.
Then you present a brute-force solution before thinking of possible optimizations. The interviewer either tells you to go ahead with it or asks some followup questions to make sure you’re going in the right direction.
Then you can get to coding. This is either done on the whiteboard or on some code pad. You rarely get to choose between the two. The whiteboard is more intimidating, but it takes longer to write, so you can think about the code while you’re writing it. Code pads usually have syntax highlighting but can usually not compile or run your code, and much less provide auto-completion. Leetcode is just like that, and that’s the reason why it’s the best way in my opinion to prepare for this kind of interview.
As you code, speak every second of the way, no matter what happens. Don’t bother writing comments unless you got a remark about some line. Write short words for variable names. Don’t write separate functions unless necessary or there are over 2 re-uses in your code. Occasionally, you can write pseudocode in long problems for obvious and repeating parts (e.g removing a node from a linked list).
Be ready to tell what the time and space complexity are when you’re done. You will be asked about possible optimizations but not asked to code them unless there’s a lot of time remaining.
If you stumble across a mechanism you didn’t know (as in my case on two interviews with Java spinlocks and ArrayBlockingQueues), you will have some difficulty with it. While that kind of interview doesn’t get you many points, it doesn’t necessarily damage your position if you manage to think about the topic logically and show understanding of related mechanisms.
I wanted to insert samples of coding problems here but this article is already long. In the next weeks, I will be posting more entries with detailed examples of coding problems I was asked through my interviews. I will keep an updated list of them here:
- Interval problems
In the meantime, this reddit thread lists commonly encountered problems succinctly and accurately in my experience. For straight practice, this is also a short resource to problems to solve by priority. Here is a longer curated list of 100 Leetcode problems.
Assignment
Assignment tasks are done autonomously over 1-3 hours depending on the nature of the task. It is sometimes composed of several Leetcode-style algorithmic problems done on some type of coding platform. Other times, you have to code a larger assignment in some IDE, in which case you will usually discuss the exact requirements. For example:
- Classic problems like a chat server, a classic Course/Student system, or a shopping cart,
- Generic exercises, like a spam filter that goes over emails and denies/allows them,
- Tasks that requires a bit of domain-specific research, like a DNS resolver or a JSON parser.
Ahead of time, you should attempt to clarify the kind of assignment you will face. Brush up on your build tools (e.g you may expect Gradle but get Maven) and study well any framework you don’t know but have to use.
Time may get short towards the end. Prioritize, and this includes letting go of the elegant way you may have mentioned you would do things, in order to accomplish all tasks. On the scoring scale, completing all items scores higher than code quality, which itself scores higher than the algorithms you used.
Further, you may receive feedback on your code, either in the form of a code review that follows the assignment, or later on during your next call. Be prepared to answer what strengths and weaknesses showed in the assignment, and how you could have improved your solution.
Architectural / design / deep dive
In this kind of interview, you either start with the interviewer asking you about a large project you recently completed on your own, or more usually you are given some problem of that type. For example, you have to approach the architecture of a message queue or the design of a system that matches taxis and travellers.
You speak in broad terms about many architectural concerns:
- How do you approach the situation?
- What kind of technologies and tools may help you?
- How do you scale or solve concurrency problems?
- How would you structure the database schema that would hold the relevant data?
In interviews that are more focused on design, you may have to write pseudocode algorithms for some of the finer nuances. This typically involves concurrency, traversal heuristics, or data structures.
Behavioral / situational
These interviews are meant to prod you on situational behavior for organizational fit. They are usually done by some kind of manager.
One important aspect of this type of interview is to come ready so you don’t leave too many voids while you think about a good case, and don’t backtrack if it ends up being a bad example.
Some classic questions include:
- What are your strengths and weaknesses? Think back to your performance review.
- What would your team leader say about you?
- What was a challenging aspect of your last job?
- What was something you did at your job and are proud of?
- What is your added value to the team?
- What is your position in the team?
- Where do you see yourself in 5 years?
Many interviewers will instead try to come from a more objective direction by asking you about past situations. The cases are not important, and the interviewers say this, as they will readily switch to another question if you’re stuck (but try to not get to that point). Hence, as you think about the cases, you can tune your story a bit as long as your reaction was real and fit how you view yourself and where you want to take your career. Some questions include:
- Tell us about a time you received positive / negative feedback.
- Tell us about a time you helped someone else improve himself over time.
- Tell us about a time you had a disagreement with someone else / your boss.
- Tell us about a time you did something on your own.
- Tell us about a time you / your team took risks.
- Tell us about a time you went over the requirements of your title.
So work on getting answers for these. You will find that each of these probably fit other questions as well, so just keep that store of situations in mind. I will also repeat the CTCI book’s advice on the matter: take some time to think of 3-4 interesting projects you had a major part in. For each of these, think of answers to these 6 questions:
- What was most challenging?
- What did you learn?
- What was most interesting?
- What was the hardest bug you faced?
- What did you enjoy most?
- Did you have conflicts with teammates?
And think a bit about probable followup questions in each case.
Technological
Finally, I have encountered a few technological interviews. Some had taken a short part of the session, some had taken the entire time.
Here, the interviewer tries to see how curious and passionate you are about tech. You will discuss many technological topics including runtime internals, containers, message queues, noSQL, garbage collection methods, latest innovations, etc. These will be interlaced with actual questions like:
- In C, what will be printed by the line
int f; printf("%d, f);, this would involve compiler behavior and registers. - The very classic question of “what happens from end to end when enter a URL and press enter?” This repo attempts an exhaustive answer.
And other more exotic ones of the type you will find on CodeKata. There isn’t much to do to prepare for this, but it helps to follow some kind of aggregator, tech channel or regular technical blog for this, as mentioned in the Resources subsection.
Mixed interviews
Take the above types with a grain of salt, as some interviews fall in several of the fundamental categories. In some cases, this is by design as some companies like to do several interviews that are half-behavioral and half-coding. In other cases, an interview can involve both a deep dive and code, or both situational and technological questions.
Evaluating
After passing each interview, it’s time to evaluate the position and decide whether to continue, unless you want more interviewing practice. You should also use the last minutes of each interview to ask questions about the position, as the interviewer will almost always ask you to do anyway. These questions are mostly laid out in the Profiling positions subsection. But with more knowledge gleaned through the interviews and through talking with HR, you can ask additional questions:
- What’s the culture within the team or department? It’s important to have nice and happy people coworkers.
- How are the development methods and discipline? For example, some departments code in slightly unique ways, like Red Hat does with open source.
- How are the advancement opportunities? Flat hierarchies will let you develop as an individual contributor (IC) more easily, but not as a manager. Top-heavy companies like Microsoft are the other way around: harder as an IC but easier as a manager. Other companies adopt a matrix management structure, allowing a hybrid tech-oriented manager, which is closer to architect but with a dash of management skills.
- If you are at the offer stage, consider the final salary, stock options, vacation days, freedom to own side-projects, working from home, studying, food, office environment, etc.
HR / Negotiating
Some recruiters play the role of behavioral interviewers and start the negotiation interview with behavioral questions. Then they get to the proper negotiation part. They usually start by explaining the benefits of working at the company, for example vacation days, studying and travel and food allowances. Then you get questions questions like:
- What is your expected salary?
- Will you consider stock options?
- Do you have any questions? This is when you ask about other benefits that haven’t been mentioned and are important to you.
I have a hard time with negotiations. Like many programmers, I don’t like bargaining. In addition, we never know what the right answers are to maximize our benefits. Most sites tell you to refuse saying any number, and instead react when you are told one. But recruiters are insistent and I can only refuse so many times.
So I have adopted a simple strategy: say reasonable numbers, get as many offers as possible and then play the competition between them. It works well, with many companies knowing that they should straight-up make a high offer, even if you said a lower number.
Recruiters will frown when you tell them about the other offers but that’s expected, as a candidate with no other offers can be a small red flag. Other recruiters will explain that your reasonable numbers are too high, in which case you should think again whether it’s even worth applying if you’ve got other offers.
Another difficult part is to leave offers hanging to have a backup plan while you get more of them. You can explain that you’re not ready to take an offer yet. Later, you can take this kind of opportunity to get more benefits from previous offers when you get better ones. Do this as much as possible and ignore deadlines as most companies will happily take you with the same initial offer if you come back to them.
In any case, companies want you. They won’t readily give up on you after all the investment they made, so push a bit until you are most comfortable with one of the offers. Recruiters have ways to make benefits shine, so always stay pragmatic.
Finally, some time after the offer is made, you get the actual contract. It can vary in length but it often contains questionable clauses. In most cases, most of the contract is non-negotiable as your recruiter only gets to tweak numbers and not legalese. But you should raise questions anyway to clarify whether they are significant. When you get the contract, the terms is usually final so make sure you negotiate well before giving any answer.
When comparing offers, don’t compare a recruiter’s speech to a competing contract, as contracts as often scarier than real conditions, in particular with working hours, remote work or side projects. Get as much information as possible from all sides before taking a final decision.
Also, be prepared for a background check at large companies. Have PDFs ready to prove your experience and education to shorten the process.
Conclusion
That’s it for now. I hope this will help some readers with the interview process. If you have questions, send me an email. Good luck!
]]>